شیائومی از MiMo، نخستین مدل هوش مصنوعی خود رونمایی کرد.
انتشار: ۱۴۰۴/۰۲/۱۴
دسته بندی:
اخبار
نویسنده:
تیم محتوا
اشتراک گذاری:

شرکت شیائومی از نخستین مدل هوش مصنوعی open-source خود با نام MiMo رونمایی کرد؛ مدلی با معماری large language و ۷ میلیارد پارامتر که برای انجام وظایف پیچیدهای همچون استدلال و تحلیلهای پیشرفته طراحی شده است. این مدل توسط تیم تازه تأسیس Xiaomi Big Model Core Team توسعه یافته است. MiMo در زمینههایی مانند استدلال ریاضی و تولید کد، عملکردی مشابه مدلهای پیشرفتهتر همچون OpenAI o1-mini و Alibaba Qwen-32B-Preview ارائه میدهد.
شیائومی اعلام کرده است که دستیابی به چنین سطحی از عملکرد در مدلی با این اندازه، یک چالش بزرگ بوده است، زیرا اغلب مدلهای موفق که از reinforcement learning (RL) بهره میبرند، به معماریهای پیچیدهتری با ۳۲ میلیارد پارامتر یا بیشتر نیاز دارند. به گفته شیائومی، توانایی MiMo در انجام وظایف پیچیده ناشی از قابلیتهای مدل پایه آن است که از طریق فرآیندهای pre-training و post-training هدفمند به دست آمده است. اندازه کوچک این مدل، آن را برای استفاده در سازمانها و دستگاههای edge با منابع محدود، به انتخابی مناسب تبدیل میکند.
شیائومی در فرآیند pre-training مدل MiMo، با استفاده از تکنیکهای پیشرفته، توانسته است به بهینهسازی قابلیتهای reasoning (استدلال منطقی) این مدل دست یابد. با بهبود سیستم پردازش دادهها و تقویت ابزارهای استخراج متن، شیائومی توانسته است تراکم الگوهای reasoning را به طور چشمگیری افزایش دهد. برای آموزش مدل، تیم توسعه یک دیتاست عظیم شامل ۲۰۰ میلیارد token reasoning آماده کرده و با استفاده از استراتژی three-stage data mixture، آن را با ۲۵ تریلیون reasoning token آموزش دادهاند. این فرآیند موجب افزایش قابل توجه سرعت و دقت استنتاج مدل میشود.
شیائومی در مرحله post-training مدل MiMo از تکنیکهای پیشرفتهای استفاده کرده است تا تواناییهای این مدل را در پردازشهای پیچیده بهبود بخشد. در این مرحله، ۱۳۰ هزار مسئله ریاضی و کدنویسی به عنوان دادههای آموزشی مورد استفاده قرار گرفتند. همچنین، برای ارزیابی دقیقتر، شیائومی از سیستمهای مبتنی بر قواعد بهره برده و فرآیند reinforcement learning را به طور مؤثر اجرا کرده است. برای حل مشکلات مرتبط با sparse reward در وظایف پیچیدهتر، شیائومی از مکانیزم جدیدی به نام Test Difficulty Driven Reward استفاده کرده است. این روش به مدل کمک میکند تا در وظایف دشوارتر نیز عملکرد بهینه تری داشته باشد. علاوه بر این، برای حفظ پایداری در آموزش وظایف سادهتر، روش Easy Data Re-Sampling به کار گرفته شده است.
شیائومی همچنین به منظور افزایش سرعت آموزش و ارزیابی مدل، از سیستم جدیدی به نام Seamless Rollout Engine رونمایی کرده است. این سیستم با کاهش زمان downtime پردازندههای گرافیکی، سرعت آموزش را ۲.۲۹ برابر و سرعت ارزیابی را ۱.۹۶ برابر افزایش داده است.
این قابلیتها، به همراه پشتیبانی از Multiple-Token Prediction در vLLM و افزایش پایداری inference در سیستمهای reinforcement learning (RL)، عملکرد مدل MiMo را به طور قابل توجهی بهبود بخشیده و سرعت آن را افزایش داده است.
نسخههای MiMo:
سری MiMo-7B شامل ۴ نسخه است:
- MiMo-7B-Base: Base model with strong reasoning potential
- MiMo-7B-RL-Zero: RL model trained from the base
- MiMo-7B-SFT: Supervised fine-tuned model
- MiMo-7B-RL: RL model trained from SFT, offering top-tier performance matching OpenAI’s o1-mini
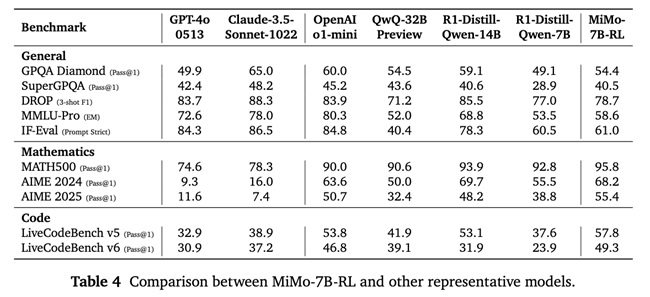
نتایج Benchmark:
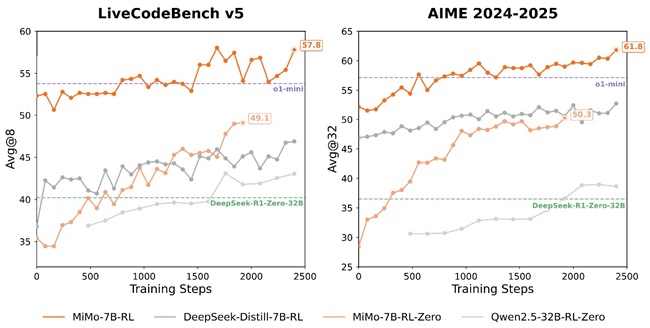
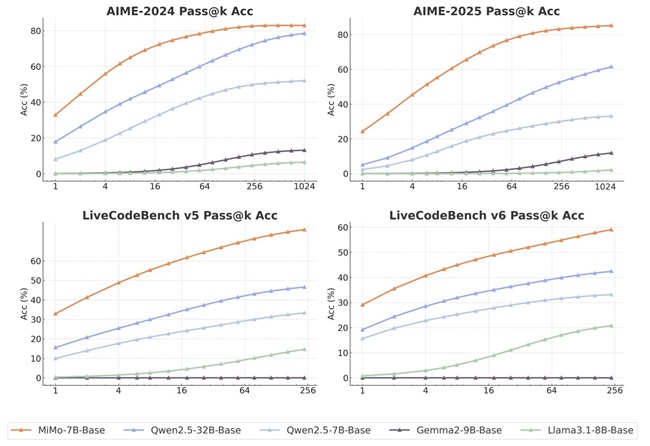
مدل MiMo-7B-RL عملکرد چشمگیری در ارزیابیها از خود نشان داده است:
در زمینه ریاضیات:
MATH-500: موفقیت ۹۵.۸٪ در اجرای اول
AIME 2024: موفقیت ۶۸.۲٪ (میانگین ۳۲ اجرا)
AIME 2025: موفقیت ۵۵.۴٪ (میانگین ۳۲ اجرا)
در زمینه کدنویسی:
LiveCodeBench v5: موفقیت ۵۷.۸٪ (میانگین ۸ اجرا)
LiveCodeBench v6: موفقیت ۴۹.۳٪ (میانگین ۸ اجرا)
سایر آزمونها:
GPQA Diamond: موفقیت ۵۴.۴٪
SuperGPQA: موفقیت ۴۰.۵٪
DROP (3-shot F1): امتیاز 78.7
MMLU-Pro (Exact Match): امتیاز 58.6
IF-Eval (Prompt Strict): امتیاز 61.0 (میانگین ۸ اجرا)
دسترسی:
مدلهای MiMo-7B به صورت Open-Source در پلتفرم Hugging Face قابل دسترس هستند. علاوه بر این، گزارش فنی کامل و checkpointهای مربوط به مدل نیز در GitHub منتشر شدهاند.
منبع: www.fonearena.com
مطالب مرتبط



نظرات
نظر خود را بنویسید
نظری ثبت نشده است

آدرس ایمیل: [email protected]
شماره تماس: ۰۲۱۴۱۷۶۴۷۲۴
ساعات کاری: شنبه تا چهارشنبه ۸:۳۰ الی ۱۷
آدرس: تهران، شهرک قدس، خیابان شهید ابراهیم شریفی، خیابان توحید یکم، پلاک ۳۷، طبقه ۲



کلیه حقوق مادی و معنوی این سایت متعلق به شرکت پارس تدوین می باشد